



服务热线
178 0020 3020
Lasso方法最早由Robert Tibshiran于1996年提出,文章发表在“统计四大”之一的皇家统计学会期刊上,尽管至今已有二十多年,但依然有着广泛的应用,由其发展出的方法层出不穷。本文着重介绍一下Lasso的原理以及2个最优解解法。
考虑线性模型:
的参数 和
的估计问题,这里
是
观测向量,
为
的设计矩阵,
是
未知参数向量,
为随机误差,
为误差的方差。
估计参数向量 的基本方法是最小二乘法,其思想是使得误差向量
尽可能的小(这样我们损失的样本信息就尽可能的少),也就是使
到达最小。解的过程略,最后,使得上式达到最小值的解为
在大数据还没兴起之前,我们接触的数据大部分都是 ,即样本数大与变量数,做计量的同学应该很熟悉,这时候,若
,则
可逆,这时,
是
的无偏估计,称
为
的最小二乘估计,最小二乘估计有很多优良的性质,在此不再赘述。但是,若
,不满秩,那这时候就不存在
的无偏估计,称
是不可估的。不满秩的原因之一就是变量间存在线性关系,在计量经济学上成为共线性,因此计量的实证分析大都要做一些检验,抛开不表。为了解决这一问题,就有了岭回归(Ridge Regression)方法,简单来说,岭回归就是在前面最小化目标函数
的后面加了一个2-范数的平方(范数接下来会讲):
上式求解就可得到 的岭估计:
从上面我们可以明显看到 保证了
满秩、可逆,当然也由于其加入,此时的
是一个有偏估计。关于
的选择,有Horel-Kennard公式、岭迹法、交叉验证法......
因为本文主要介绍Lasso方法,在此不再做过多介绍,感兴趣的同学可以自行查阅相关资料。
向量的 1-范数: 向量内各元素的绝对值之和
向量的 2-范数: 元素的平方和再开平方,一般就直接写
不加下标了。
向量的 p-范数:
向量的无穷范数:
矩阵的 1-范数: 矩阵的每一列上的元素绝对值先求和,再从中取个最大的(列和最大)
矩阵的 2-范数: 其中
为
的特征值,2-范数即为矩阵
的最大特征值开平方。
矩阵的无穷范数: 矩阵的每一行上的元素绝对值先求和,再从中取最大的(行和最大)。但还有一种情况,在很多的统计论文中,更常用的是把矩阵的无穷范数定义为矩阵中最大的元素:
这里只是借机会都给大家列出来了,本文并不需要用到这么多种范数。
与岭回归类似,Lasso就是在目标函数 后面加了一个1-范数
Lasso的提出在岭回归之后,为啥加1-范数的Lasso没有加2-范数的岭回归早?
可能是因为1-范数作为绝对值之和不方便求导吧(个人猜测),因为做理论统计的学者提出一个新方法,不光要说明这个方法好,还要说明为啥好、哪里好。
为什么至今Lasso仍长青不老?
因为它可以解决现在高维数据一个普遍问题——稀疏性。高维数据即 的情况(超高维是
,这里不讨论),现在随着数据采集能力的提高,变量(也叫特征)数采集的多,但是其中可能有很多特征是不重要的,系数很小,如果用岭回归,可能这个不重要的变量也给你估出来了,而且可能还不小,而用Lasso方法,就可以把这些不重要变量的系数压缩为0,既实现了较为准确的参数估计,也实现了变量选择(降维)。
那为什么Lasso可以估计出系数为0?
我们以Tibshiran在文章中举的 的例子来讲(我这相当于把他文章的2.3节翻译给大家了)
首先我们假设 是满秩的,这样就可以用最小二乘法估计出来
,对于
,它也可以写成
,在下图中以椭圆表示:
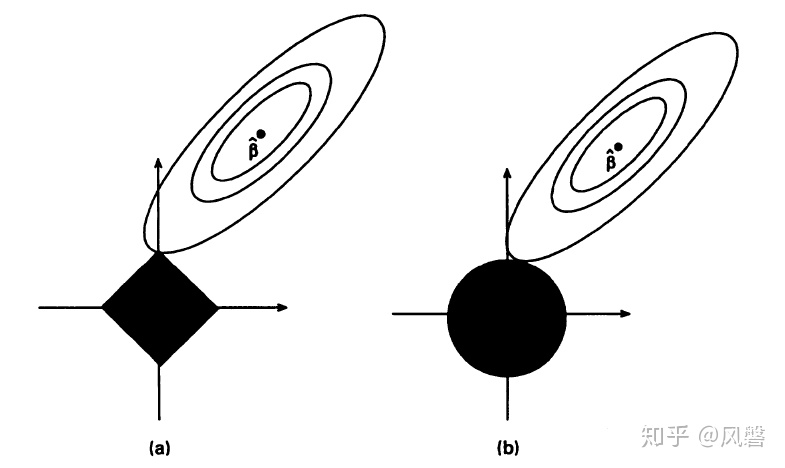
上图中(a)是Lasso估计图(b)是岭回归的估计图,横纵坐标分别表示 ,黑色部分表示两种方法的约束
从图中可以看出,Lasso方法与之相交的地方恰为 ,而从图中也可以看出
所处的位置本就是
大,
小,我们取Lasso的结果,意味着
的系数被压缩到了0。
你可能觉得,这个交点离着 也太远了吧,这里要解释两点:一是做这样的图是为了更直观,所以有所夸大。二是,不管Lasso还是岭估计,它们都是有偏估计,肯定会与通过最小二乘法得到的无偏估计
有差距。
Lasso因为其约束条件(也有叫损失函数的)不是连续可导的,因此常规的解法如梯度下降法、牛顿法、就没法用了。接下来会介绍两种常用的方法:坐标轴下降法与最小角回归法。
坐标轴下降法是一种迭代算法,与梯度下降法利用目标函数的导数来确定搜索方向不同,坐标轴下降法是在当前坐标轴上搜索函数最小值,不需要求目标函数的导数。
以2维为例,设损失函数为凸函数 ,在初始点固定
,找使得
达到最小的
,然后固定
,找使得
达到最小的
,这样一直迭代下去,因为
是凸的,所以一定可以找到使得
达到最小的点
。(如下图)

在 维的情况下,同理,参数
为
维向量,固定
个参数,计算剩下的那个参数使得凸函数
达到最小的点,
个参数都来一次,就得到了该次迭代的最小值点。具体来说就是(以
表示第
次迭代第
个参数的值):
你可能会有疑问,我最后得到的 只是局部(因为固定了其余
个)最优解啊,为什么
就是全局最优解了? 这是凸优化问题的一个基本性质——任意局部最优解也是全局最优解。感兴趣的同学可以参考Stephen_Boyd的《convex optimization》第4.2.2节,清华大学出版社有中译本。
最小角回归法(LARS)是Bradley Efron于2004年的论文《Least Angle Regression》中提出的一种算法。该算法与经典向前选择(classic Forward Selection)算法接近,我们先简单介绍一下向前选择算法,以2维为例: ,为了估计出
,我们先将
往与其最接近(相关性最大)的
上做投影,假设与
最近,得到
,然后残差往
上做投影,得到
,over。(如图所示)

最小角回归算法与之类似,但不像向前选择一样"贪婪",按照论文上的说法是这样:
与经典向前选择算法一样,我们所有的系数都从0开始,然后找到与相应变量最相关的预测变量
,比如
。我们朝着这个预测变量的方向尽可能的迈出最大的一步,直到另一个预测变量,比如
,它与当前残差有与
与当前残差有与
相同的相关性,然后沿着
的角平分线前进,即:最小角方向。直到第四个变量进入,然后以同样的方式继续下去。
接下来我们以2维为例作图说明,关于相关性,为了更直观给大家表示,我们选择皮尔逊(Pearson)相关系数,因为Pearson相关系数在数值上等于角的余弦值。
如果你是第一次知道Pearson相关系数等于两向量的余弦值,我举几个例子:两向量同方向,夹角为0,余弦值为1,Pearson相关系数为1,若两向量垂直,则余弦值与Pearson相关系数为0,若完全反方向(夹角180度),余弦值与Pearson相关系数为-1。因此,夹角越小,说明相关性越大。

这张图只是尽可能的还原论文中的图,实际中,并不一定正好有,至于为什么没用原论文的图,因为我下的论文不知道为啥图片是糊的。
从这张图上我们可以看到,一开始, 与
夹角更小(相关性更大),于是沿着
的方向走,走到
和当前残差相关性相等的地方,开始沿着
的角平分线前进(即
的方向),至于最后正好与
相交,是巧合,不要被误导以为这个算法就能完美估计出来参数。
最后说一下,Lasso方法不管是在Python还是R上都可以轻松实现,调用包以后只需要一行代码就可以求出结果,就不讲了。这里要说一下一开始给出的公式
其中的 在软件中一般以交叉验证(CV)得到。但同时我们也有其等价定义
这里 选择的越小,参数被压缩到 0 的越多,如果
非常大,系数就基本不会被压缩,以Lasso论文中的图片为例:
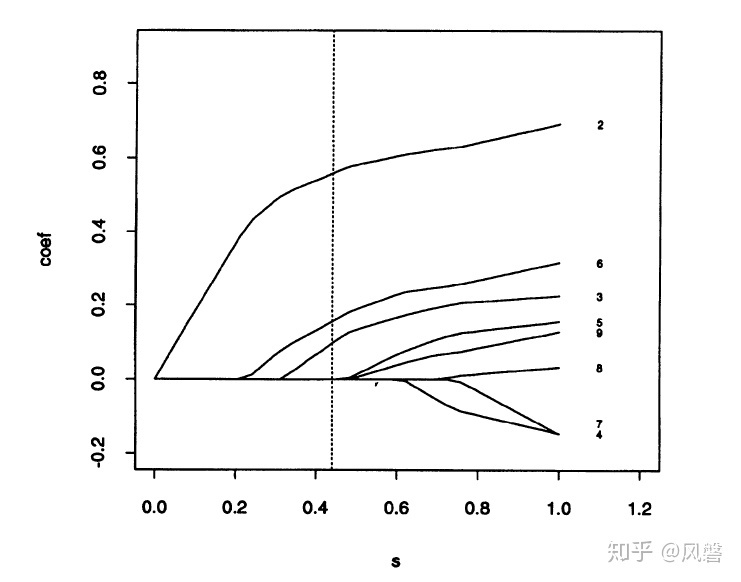
横坐标 就是公式中的
,这里虚线表示
,这时选出来了三个变量,其余变量的系数都被压缩到了 0。从图中我们可以看出,若
,那就只剩一个系数了,若
很大,所有系数都不会被压缩。
之所以放上这个图,是因为软件输出结果会出现这种图,如果我们需要一定的变量数,而通过CV选出的太少,可以根据这图手动调参,使输出的系数符合我们的要求(当然其他指标如残差平方和也会有所变化)。
原文链接:https://zhuanlan.zhihu.com/p/116869931

附件