



服务热线
178 0020 3020
从字面上来理解,绝对定量就是“绝对的”,就是想知道某一份样本里靶标DNA到底有多少拷贝,不因任何其他样本的情况而发生改变。绝对定量的输出结果一定是与拷贝数相关的,如copies/ml blood, copies/μg Total RNA等。Blood和Total RNA叫做Normalizer,均一化因子,可能很多人会误以为绝对定量不需要均一化,这是完全错误的。Normalization是为了所有样本可以在同一条基准线上进行比较参考,copies/sample这样的单位是没有任何意义的。
Normalizer
绝对定量实验中常用到的normalizer包括取样组织的体积或质量、提取到的总RNA或者基因组DNA的质量、起始细胞的数量(如流式分选的细胞)和spiked-inexternal control等。External control如果在核酸提取前加入,会对提取效率有很好的评估。选择哪一种normalizer取决于实验背景和目的,但有一个统一的准则是,选择的normalizer能够提供更严格的均一化标准。称取组织重量的误差与流式分选计数的误差孰大孰小?定量AIDS患者体内的HIV载量,采用copies/ml blood作为单位还是copies/105 CD4+ T cells更为合适?类似的选择见仁见智。个人认为,使用HIV的主要感染对象作为单位进行评估更为合适,可以尽量减少CD4+ T cells数量的个体差异带来的偏差。
模板
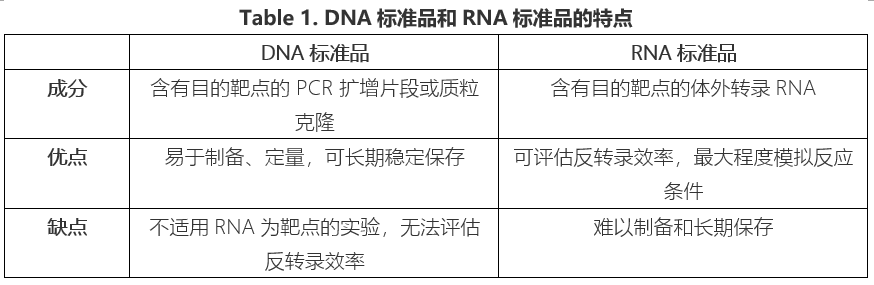
用于建立标准曲线的模板一般是DNA或者RNA标准品,浓度是已知的。两种标准品各有优劣(Table 1),根据具体实验灵活选择。尽可能选择商品化的标准品,当条件不具备时再考虑自己制备。
模板要尽可能模拟样本的组分环境,最后的定量数据才会尽量接近真实值。标准品一般是均质的,且靶标核酸分子纯度很高,而实际样本中不可避免会存在其他物质,干扰PCR反应的进行,效率下降,从而导致最后的定量数据偏低。推荐使用实际样本的基质对标准品进行稀释,比如检测肿瘤病人血浆cell-freeDNA(cfDNA)中SNP突变,那么可以使用健康人血浆中提取的cfDNA。
梯度设置
标准品的浓度是很高的,可达108-1010copies/ml以上,这个浓度在实际实验中是用不到的,需要进行稀释。我们要决定曲线中最高的浓度点S1、梯度的数量N和最低的浓度点SN。N要大于5,取6或7是比较合适的,更多的梯度在提高数据精度的同时不可避免增加试验成本。S1和SN取决于具体实验样本中的靶标浓度,S1比预测的最高浓度高5-10倍,SN比预测的最低浓度低5-10倍是比较推荐的,但也视具体情况而定。一个大致的原则是,浓度梯度必须覆盖实验中所有未知样本的浓度,同时使S1和SN离未知样本中的极端浓度点尽可能的近。
假设预测未知样本的靶标浓度都在10-200copies/μl之间,一个合适的方案是,S1到S7分别设为1000, 200, 100, 50, 25, 10, 2 copies/μl。要注意的是,稀释比不需要保持一致,”两头宽中间密”的设置方法可以最大程度保证数据的精度。
靶标浓度的预判要基于一定的背景知识或者之前类似的研究报道。一个备选方案是,预先随机抽取10个样本进行测试,计算Cq值的99%置信区间。从Cq值到拷贝数的推算方式是,39或者40对应反应体系中1-2个拷贝,按照扩增效率为100%,30对应1000-2000个拷贝,这样的估算误差是可以满足要求的(5-10倍的容错空间)。
因为绝对定量完全依赖标准曲线,因此稀释操作的质量会直接决定绝对定量实验的准确性。每一次稀释操作的稀释倍数不能超过10,同时尽可能用大体积体系配制,如10倍稀释至少要5 μl + 45 μl的模式,而不能是1 μl + 9 μl。尽量不用2.5 μl量程的移液器,其他移液器的移液体积至少要量程的一半。每一个梯度必须完全混匀后才能进行下一个梯度稀释。
重复的数量
做标准曲线时每个梯度都要有至少3个技术学重复,这是最低的要求。更推荐6个技术学重复,去掉最大和最小的Cq值后剩余的取平均数即可。技术学重复数量的增多对于提升数据准确性具有显著的效果,相比2个重复,4个重复可以将SD降低30%。
数据分析
前面所做的所有努力都是为了拿到类似于下面这样的标准曲线(Fig1)。相关系数R2要求大于0.98,如果不满足,可能要考虑删掉重复性差的梯度点(一般是浓度最低的)。扩增效率E也可从方程的系数中推导出来,之前在“qPCR的原理”一篇中有详细的推导过程。
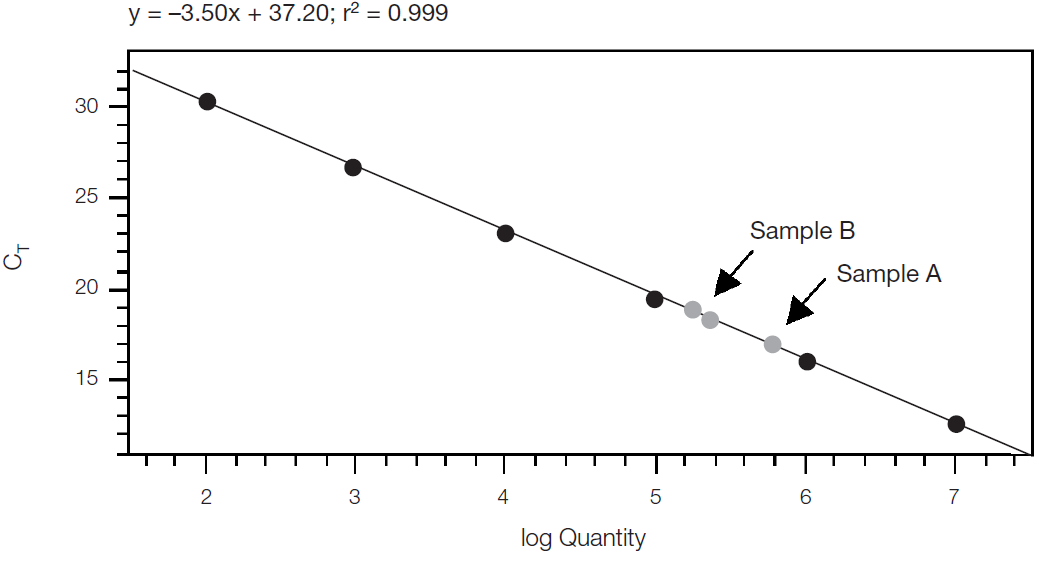
Figure 1. 标准曲线方程
一般要求未知样本也要做三个重复,先算出Cqmean,再将其带入y,就可以根据x求出靶标的浓度。也有人通过Cq的三个重复分别算出三个靶标浓度再算mean值,这是不合理的,Cq和Quantity是指数的关系,Cq值的很小的差异就会造成Quantity很大的变异程度,因此Quantity是不适合用算数平均数的,而应该用几何平均数(对应Cq的算术平均数)。

附件